
OpenAI a lancé trois nouveaux modèles audio dans son API Realtime, ce qui représente une avancée majeure pour tous ceux qui développent des applications vocales. Ces trois modèles sont GPT-Realtime-2, GPT-Realtime-Translate et GPT-Realtime-Whisper.
Ensemble, ils font évoluer l'IA vocale au-delà de simples échanges de réponses pour aboutir à une technologie capable de vous comprendre, d'agir et de suivre le rythme d'une véritable conversation.
Si l'on en croit leur démonstration, nous venons d'assister à la prochaine étape de l'évolution du fonctionnement des modèles d'IA vocale.
Alors, que peuvent réellement faire ces modèles ?
GPT-Realtime-2 est la vedette. Il apporte un raisonnement de classe GPT-5 aux interactions vocales en direct, ce qui signifie qu'il peut traiter des demandes plus complexes sans perdre le fil de la conversation.
Il peut faire appel à plusieurs outils simultanément et même décrire ce qu’il fait avec des phrases telles que « je vérifie votre agenda » ou « laissez-moi voir ça ». Il dispose également d’une fenêtre contextuelle plus large de 128 000 tokens, ce qui permet des sessions plus longues et plus cohérentes. Les développeurs peuvent même ajuster l’effort de raisonnement en fonction de la complexité de la demande.
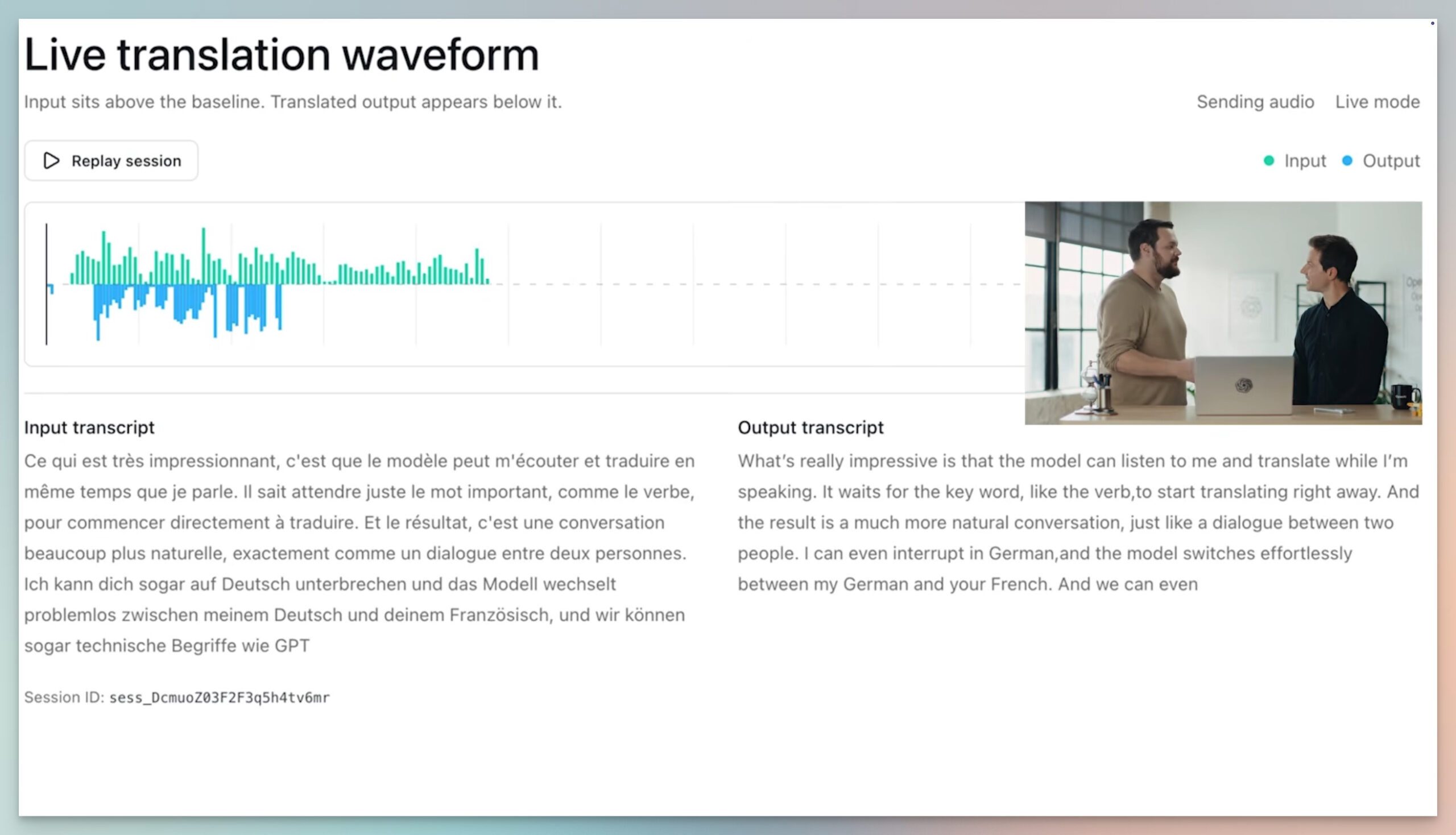
GPT-Realtime-Translate est sans doute mon préféré. C’est ce qui se rapproche le plus, dans la vie réelle, du traducteur universel de Star Trek. Il prend en charge la traduction vocale en direct dans plus de 70 langues d’entrée et 13 langues de sortie.
Le plus impressionnant dans la démonstration, c’est que même lorsqu’une nouvelle personne se joignait à la conversation et parlait une autre langue, GPT-Realtime-Translate n’avait aucun mal à traduire en anglais les propos des deux interlocuteurs en temps réel.
Enfin, il y a GPT-Realtime-Whisper. La plupart des modèles de reconnaissance vocale attendent que l'orateur ait fini de parler avant de fournir la traduction complète. Celui-ci est un modèle de transcription en continu qui convertit la parole en texte au fur et à mesure que l'orateur parle. Il est utile pour les sous-titres en direct, les notes de réunion et tout flux de travail vocal où il n'est pas possible d'attendre une transcription.
Tout le monde peut-il utiliser ces nouveaux modèles d'IA vocale ?
Actuellement, OpenAI a mis ces modèles à la disposition des développeurs. Mais les applications qu’ils créeront auront un impact sur tout le monde. Par exemple, un développeur peut créer une application de traduction en temps réel, permettant aux utilisateurs de converser avec des personnes parlant différentes langues.
De nombreuses entreprises testent déjà ces nouveaux modèles. Zillow développe un assistant vocal capable de rechercher des logements et de programmer des visites à partir d’une simple demande vocale. Priceline peut vérifier vos vols et vos hôtels, les annuler et en réserver de nouveaux. Vimeo l’utilise pour la transcription en temps réel, et ainsi de suite.

Les tarifs commencent à 0,017 $ par minute pour Whisper, 0,034 $ par minute pour Translate et 32 $ par million de jetons d'entrée audio pour GPT-Realtime-2.


